—— Case Study ——
How Agilent's Global Software Team Doubled its Productivity

In 2015, we undertook a lean / agile transformation journey at Agilent Technologies that resulted in doubling our productivity over three years. Along the way we learned about teaching a large global team to do coordinated agile development; the leadership conditions that drove success working smoothly with outsource vendors; and partnering with our IT department. We’ll cover struggles with repairing field quality, delivering on a cadence, and building credibility and trust over time with customers and internal partners. Supplemental papers available on the TCGen website provide more detail on many of these topics, agile principles, metrics, and practices.
Many people contributed to the success recounted here. Most are unnamed for the sake of brevity. I’ll use “we” to acknowledge those contributions.
Background
Agilent Technologies is a multinational manufacturer of Instruments, software, and services for life sciences and healthcare industries. Headquartered in California, the company has offices across the globe. Sales are mainly B2B, and the company serves regulated markets including Pharmaceuticals and Healthcare. The Software and Informatics Division (SID) at Agilent has exclusive responsibility for enterprise software products. Its lab data systems provide support for a range of Agilent and third party instruments and are designed to be deployed in a variety of configurations. When I joined the company in late 2014, these were all on-premise.
Competitors Waters and Thermo had newer lab software that was a better fit for enterprise customers about 80% of the installed base. It offered more instrument coverage, it was easier to use, and localized for China, where there was explosive growth in analytical test labs. Dominance in enterprise software for labs meant that they could charge a toll to connect competitive instruments like ours. The toll forced discounts on the prices of our instruments. Low-end competitors eroded instrument prices from below. As a result, there was very little pricing power at the low and middle market, and discounts reached levels that would embarrass a consumer audio retailer. It was clear to our CEO and sales leaders that winning in software was key to owning our destiny. There was strong C-level sponsorship for the company to reinvent its software offerings and its organizational capability to deliver software effectively.
The Challenge
In the winter of 2014, Agilent’s Software and Informatics Division employees were not happy. They were under pressure to deliver a modern replacement for their venerable but aging Chemstation and EZChrom software and they had slipped their delivery date several times. They had persistent field quality problems with their legacy products, and the sales and support team were skeptical of the SID team’s empathy for customers. Customers were annoyed and did not want to talk about new software: they were seeing quality issues and a history of inaction on past requests. Why spend more time talking if nothing will change?
I took the SID General Manager role in winter of 2014. My predecessor and his senior leaders intended to retire, but were open to staying on to help me transition and hire their successors. The previous team had fought to establish an independent software division in a hardware company and get its portfolio and funding consolidated. The next step was clearly to build credibility and trust.
SID was a global team. We had two main sites in California and Germany, plus smaller ones elsewhere in Europe and a large outsource partner in Pune, India. There were about twenty scrum teams at that time working on new and legacy software - eight products in all. The division had its own support team, but the lab software sales specialists reported to the company’s global sales leaders, and I had been told to move the deployment team from within the division to the company’s services business unit. The division’s people were smart, experienced, and motivated, but they were stumbling in execution. The team’s ideas about what mattered in the market were at odds with the views held by sales and support, especially with respect to the importance of serving the large installed base. We heard frustration from long-time customers as well, especially those that had bet their future on products that were no longer the focus of investment with the push to deliver new software.
We served several markets. The two largest were pharmaceuticals and the chemical and energy industries. The first was highly regulated, and needed software that resisted tampering and supported regulatory audits. Chem/Energy needed software that was very easy to use and focused on fast cycle times and highly specialized analyses, sometimes at remote locations, conducted by technicians with minimal training. We had underinvested in both of these constraints, and as a company we had a fragmented software portfolio with as many as 50 titles covering instruments in the lab rather than one (as our competitors did) for most of their routine instruments plus those of competitors. There was a great deal of catching up to do.
I resolved to take 90 days to observe, meet and get to know people, begin to learn the business, visit customers, develop a strategy and plan, hire my leadership team, and write up our observations and a set of goals in cooperation with my boss.
There had been a great deal of focus on silo financial performance in the prior administration. Mike McMullen, incoming CEO at the time I joined, asked us all to focus on our customers and to act like one company rather than a collection of silos. In a private meeting I once asked Mike what I ought to do if doing right by a customer meant we had to take a P&L hit. He said that if it came to that, do what’s right for the customer, keep track of the expense, and he would find a way to make us whole. As it happened, I never had to make a sacrifice large enough to call in that promise, but it was liberating to know that our CEO was willing to back his talk with cash.
Observations
We found a range of issues holding the team back, including fear of failure, execution challenges, and a lack of customer closeness.
Too many systems of record
At the operational level, we had multiple systems for tracking work that didn’t talk to each other, so there was no easy way to see all the work requests and commitments in one place. The system that tracked support tickets was a rich source for defect reports and other customer information, but it did not connect to the systems of record used by the developers. Nor did the company’s CRM system. Developers used at least two systems, and our outsource vendor used another for tracking work.
Too many approaches to agile
Some dev teams used a Kanban approach to work, others based their approach on Scrum. Each team had its own idea of what “agile” meant and how to do it. Estimates were not comparable from one team to another, so it was hard to get a clear idea of how much work capacity was available or what could fit into a release. In small scale agile development, the canonical unit of estimation is a “story point” and industry dogma is that a story point is an arbitrary unit. This makes it impossible to estimate how much effort will be required to deliver a capability that spans teams or sprints. Portfolio level thinking is a grind.
Long build cycles
Builds required multiple transatlantic hops and took a week if they succeeded at all. Builds failed at least as often as they succeeded, and with the long cycle time, it could take even longer to track down the problem and fix it since developers had moved on to other work by the time the build failed. Tests were mostly manual, and because of the integration issues, they tended to happen late and therefore had a high surprise factor. The overall result was that the system wasn’t integrated most of the time. It was hard to do demos to get stakeholder feedback, and there were plenty of late breaking surprises to contend with since integration tests happened late and there were fewer demos than desired.
Quality debt
Persistent field quality problems with legacy products meant that the development team were constantly interrupted with fires to fight, but because of schedule pressure the team made relatively cursory efforts to deal with them. Some serious field issues had aged for two or three years with no resolution. The result was frequent interruptions from upset customers, an angry support team, and frustrated sales reps. This made it even harder for developers to meet other commitments. Nobody was happy.
Unsafe culture
The team feared bringing bad news to leaders, so they downplayed risk and uncertainty, and bad news often got revealed too late for leaders to marshal help. There was a tendency to expect the Quality team to “get out of the way” rather than hold R&D accountable to high standards and drive improvement based on evidence. This was part of the reason for the persistent field quality issues. We had a major schedule slip a month or two before the promised release date of the new software. It was an opportunity to see the results of an unsafe culture.
Emailing the buck
The team overused email, and this caused decisions to eddy even at the developer level. This seemed to be a company culture issue. It looked as if people felt their job was done when they passed an email request on to someone else rather than when the problem was solved.
Unclear scope
We lacked clarity on the scope of the work. Stories were often confusing, and could be bigger than a team could complete in a sprint. There was a perception that features and scope were more important than time to market. Quality and reliability tended to go begging. Our Product Owners had not coalesced into a guild or practice area, and story quality was not what it needed to be. At the Product level there was a sense that “if we don’t have everything, we have nothing” meaning that nobody would buy our new software if it didn’t do everything the old software did. We would go on to prove this untrue, but it held us back by causing people to overemphasize scope early on.
Strong Opinions, Weak Evidence
There was a great deal of reliance on expert opinions and not nearly enough evidence available to substantiate or refute them. Many employees had been in the market and with the company for decades, and had earned PhDs in related fields. They had grown up as chemical analysis or life sciences specialists. Our customers were increasingly not specialists, and purchasing power at major accounts had shifted from scientists to procurement and IT departments. The organization reflected the market of two or three decades ago, and were slow to change thinking to reflect these new conditions.
Software As an Afterthought
As a software business in a hardware company, we found that software was an afterthought if it showed up at all in accounting models and other sources of internal evidence that worked well for hardware sales. Leads in our CRM system were tied to hardware SKUs rather than software unless the sale was software only, so we had no win/loss information other than anecdotes from sales reps. We had no way of knowing what software attached to what hardware, or where our installed base was. We could see sales by quarter, sales region, and product or product line, but that was about all. We needed data to understand our sales and our market independently.
Archaic Licensing System
We had underinvested in developing sources of evidence of our own too. Our ancient licensing system was obsolete, coarse, and poorly instrumented. It required manual administration. There was little ability to control feature mix in the software based on the license. We also discovered that there were license leaks when we delivered upgrades. The choices the team had made twenty years ago in the license system were still locked in, and hampered the marketing team’s ability to deliver or even think about new business models. We couldn’t see how our software was attached to other orders, or vice versa.
Transformation Steps
First Step: Build Trust and Credibility
It was clear that we needed to build trust and credibility, so our first step was to improve our predictability - to deliver what we promised and get field quality issues under control. Knowing that we had to delay the launch of our new product, we decided to take the time to restructure and transform the way we worked with the expectation that this delay would pay off later.
Five Key Elements
In our shared conference room I hung a handwritten poster emphasizing five key points for us to bear in mind as we went about changing the way we worked. Predictability, Teamwork, Evidence, Simplicity, and Customer focus became the principles that drove our transformation. In our operating plan we defined and expanded on these ideas.
Predictability comprised three objectives. First, doing as we said we would do, or giving timely warning if we were in trouble. Second, a clear way for stakeholders to request work from us, with a transparent decision process. Finally, meeting our customer commitments. A corollary is being careful about what promises we made. It’s OK to say “no” as long as there is a good reason.
Less Email, More Communication
Observing Agilent’s tendency to overuse email,we asked people to converse directly in person or via audio or video calls whenever possible, to speed decisions and results. It looked like part of the silo culture led people to think in terms of checking off their own to-do list rather than solving problems. We needed to get our people to own problems and solve them together.
Creating an Evidence-based Culture
We were a company of very bright people who had grown up in labs like those of our customers, so there were many strong opinions, but often those opinions were out of date or not informed by a broad perspective on the market. We had to get people to develop and rely on evidence, recognize conflicting opinions, and ask for evidence to make well-informed decisions. This helped take egos out of discussions, and gave more agency to people who had not had as much customer contact. Relying on evidence wherever possible also created the psychological safety the team needed to emerge from its conflict-averse prior culture. We leaders also did our best to model candor and show the team that speaking up was encouraged, that good ideas could come from anywhere, and that bad news delivered in a timely way was a good thing.
Putting Customers – Not Silos – First
The team tended to tolerate or even embrace complexity rather than look for ways to make things simpler for ourselves and our customers. There was a definite tendency in the company for divisions and departments to act independently to optimize their perceived interests even when it inconvenienced customers. This spilled over into product design: it was a major win for the company to adopt a common industrial design for the power switch across all instruments. Our software reflected this - it was highly flexible and capable for specialists, but not easy to use for enterprise customers who increasingly staffed their labs with less expensive techs and needed a simple and common way to run most of their lab workflows. The market was moving rapidly toward labs staffed this way, with supervisory roles reserved for specialists. We needed to catch up. Customer focus means putting customer interests ahead of parochial ones, and getting* out of the building* to understand more deeply who our customers were and how they worked with products like ours. Customer collaborations eventually became a source of growth and learning for us.
Taking Action
One Place to Track Work
After setting out these principles, we decided to first create a single place to track our work. We had too many systems of record and multiple approaches to development in our team. From a combination of kanban and “agile in name” approaches we decided to converge on doing Scrum one way across all teams, and engaged consultants from TCGen and Cprime to help us develop a common practice. We included our outsource teams in this training, and expected outsource teams to use our tools and processes, and not something else. We chose two week sprints and a rather long nine month release cycle initially, and trained all of our teams the same way. We migrated all of our work into Jira and Confluence, and began to discuss connecting our support ticket system so that support tickets could be tracked to defects. This is a short description of a heroic effort on the part of the team at SID as well as our partners in IT. Having one approach and one tracking system meant one dashboard for all that work. It enabled a consistent review format from program to program.
Regulations and validation
Our industry was just beginning the transition to cloud computing when I joined Agilent. Lab informatics software was mission critical for production in most of our customers’ labs, and they were very cautious about making changes that might disrupt work. Lab and IT managers had to do a great deal of testing and documentation when they deployed an upgrade, but still wanted bugs fixed quickly with no extra baggage to test. We took care to distinguish between releases containing only bug fixes, and releases that contained new features and capabilities (Feature Releases, which were numbered from FR-1 onward). Bug fix releases could be tested at much lower effort as long as customers trusted us to have good release discipline. We chose a nine month feature release cycle initially, as much because of our own build and test cycle times as the market necessities of on-premise software. Later, we found ways to shorten those cycles dramatically, but the market still needed what it needed.
Program Office
We set up a program office tasked with improving our business processes and leading interactions with our many stakeholders in other divisions - the beginning of portfolio management. Our program director led monthly Portfolio Management meetings to create a transparent way of requesting work from us, negotiating, and communicating decisions. We encouraged the senior leaders of other divisions to participate and help develop clear priorities. It wasn’t easy!
The program team also led our large Sprint Zero meetings and the planning sessions that led up to each Sprint Zero, kicking off the feature release cycle. One of the critical roles of the program office was to work with stakeholders to get a clear ranked feature list far enough ahead of each Sprint Zero that there was time to negotiate a scope that would fit in our available capacity. This involved a great deal of back and forth as initial estimates often exceeded our capacity by a factor of three! Over time, the team got better at planning and estimating - only up to the “fill line” - to avoid wasting time planning things that had no chance of fitting in the release.
Project to Product Mindset
Culturally, our team and company were in a project mindset. A new release effort started with the inbound marketing team defining what they considered to be a minimum scope necessary for the effort to make a return that the company considered necessary to justify the investment. Because releases were frequently delayed – in part because of the insistence on fixed scope – marketers often were unsure when they would get another chance to get a capability to market. As a result, they tended to ask for everything when they had the chance. This helped perpetuate a vicious cycle of underestimation and slips. One of the hardest things I had to do as GM was to drive the team toward putting quality and cadence ahead of scope.
It was difficult for the team, used to the old way of doing things, to come to terms with the idea that we would sacrifice scope in order to hit a release cadence, or even more improbably ask the developers to stop planned work and help customers resolve issues with our software. As it happened, exposing developers and our leaders to hot customer situations, sometimes by flying teams to customer sites, was a revelation for many. They came back with enthusiasm and a greatly improved first-hand understanding of why our products mattered and how they were used in real life. Spreading customer insight into the development team made story writing simpler and led to both better design decisions and more give and take between developers and product owners.
My senior leaders and I had to work hard to convince the team that Scope must come after Quality and Cadence in the canonical priority list of development. In hindsight, this was one of the biggest struggles in making the change succeed, and it was likely that teams would easily revert to prior practice without ongoing leadership commitment.
If you knew scope might get ejected late in a release, you would do some things differently. A first change would be to attempt to complete as much as possible as early as possible in the release. The more scope is complete, the less risk there is of having partially finished work at the end. So rather than doing fifty things in parallel for the whole release cycle, a good adaptation might be to focus and finish ten things at a time, five times over. Knowing that some scope might have to be ejected, it’s also a good idea to have work in progress that is always in a usable and tested state, so that partial work can be released. This is a core idea of agile development, but teams may fail to do it unless they have very good habits. One way of enforcing these habits is to have a very frequent and regular demo cadence, and to require that stories pass testing before they are considered done. This is part of good “Definition of Done” hygiene.
Customer Commitment Focus
One immediately helpful change was to create a marketing role responsible for meeting customer commitments, which included resolving defects in a timely way. I asked the leadership team to model commitment to quality by attending a brief weekly conference to direct action on critical issues. Our incumbent quality leader took the role and flourished in it, and I had the opportunity to promote another quality leader who had not been immersed in the “get out of the way” culture but instead was passionate about building a forceful quality team and driving improvement. We set a goal to release a patch for 80% of critical or serious field defects within six weeks as a way of formalizing our commitment and measuring progress. As it turned out, we were so successful that we had to change the goal. There were so few outstanding field defects after the first couple of releases that it was hard to meet our target.
Paying Down Quality Debt
We asked one of our engineering directors to lead a program to work down our quality debt of aging field defects in legacy products. We dedicated a team of developers to this and asked them to visit customer sites to gather the information they needed to identify root causes. We had developers and managers returning from field visits as heroes for our customers, with new enthusiasm and understanding of how our products were really used, and new insight to bring to their work. It felt like we won in more ways than working down the quality debt. Having developers with a deeper customer understanding made the work of Product Owners simpler too. The net result of our efforts to pay down quality debt was renewed credibility with key accounts, and with our sales and support people. This led directly to growth in upgrades, and reduced the amount of time our team was spending fighting fires, increasing productivity.
Product Life Cycle
Our Quality director made changes to our Product Lifecycle that specified how our agile development process fit into the traditional gated process that was standard at the company, and which was necessary for us to meet our regulatory commitments to our customers. We found a relatively simple way to achieve this that gave us the freedom to do periodic releases without excessive documentation.
Investment in Architecture
We found that our legacy products had outgrown their designs and toolchains. In many cases we had products stuck on old versions of compilers or key libraries because of underinvestment in architecture and devops. We saw this issue beginning to develop in our new product as well. There were ad hoc decisions intended to get the product to market that had led to performance issues or that made it more difficult to adapt our learning about the market once we had launched. To correct this we decided to create an architecture group. Our intent was to signal our commitment to being deliberate about architecture in our products, to develop a culture around architecture, and to establish a clear architectural vision for our products that was tied clearly to the direction of our markets. We wrote architectural reviews into our Definition of Done – effectively giving the architects the power to shape releases if they needed it. Over time the architects developed what we came to call our target architecture and a roadmap to achieve it. We allocated a significant fraction of our development capacity in each release to implementing capabilities that made progress toward our target architecture.
Unbreaking the Build
Initially we were lucky to get one build done per week. Our buildmaster installed traffic lights over each scrum team’s work area to show where the build had broken. If your build passed successfully, your light would be green. If you broke the build, everyone could see that red light. It was amazing how quickly broken builds got resolved after that. We still had a long build cycle, but overall we moved to several builds per week.
Over time we set up a devops team and asked them to cut build cycle time with the goal of having a build plus smoke test take no longer than a coffee break. We also invested in improving our automated test coverage at multiple levels – unit, functional, and integration testing. The QA team used low-code test development tools for UI and integration level testing, and our developers did the lower level work. The devops team came up with ways to automate the creation and loading of virtual machines to perform load testing. They brought test coverage up and cycle time down to about thirty minutes over the course of a couple of years.
Product Owners and Story Quality
Product Owner is the most challenging job title in agile development. A PO must be insightful about the end use of the product and its domain, while also being able to translate requirements into clear, concise stories that developers understand and estimate. They must work well with both developers and marketers. They must be good negotiators and have enough grasp of business to be able to identify value and work with evidence to justify their backlog rank decisions. We did not have a strong PO community initially. Story quality and customer connection both needed work. To address this, we organized PO’s under a single leader globally and worked to create a culture around product ownership practices and continuous improvement.
Making a Capacity Model
In our first feature release (FR-1) we saw that the amount of work requested of us was at least three times what we had capacity to complete in the release, but it took a great deal of estimation effort from our most senior technical people and POs to realize that. Part of the problem was that we did not have a way to estimate how much capacity was actually available to assign to new requests. As a result, we wasted precious effort estimating work that had no chance of fitting in the release, and set incorrect expectations about what could be accomplished. I asked our Program Director to lead the development of a capacity model so that we could do a better job estimating those features that would actually fit next time.
We had a single system for tracking work and work requests. We decided to buck the current teaching in agile development and ask all of our teams to use a reproducible unit of work so that we could compare estimates and add them up. We defined a story point as the work a developer could accomplish in a day. From this foundation we were able to create a relatively simple model that gave us a good estimate of the capacity to deliver stories to market, as well as an estimate of where the rest of our capacity was going. Initially we found we had only about 30% of our capacity available for discretionary work. The remainder was to address quality issues, both field defects and defects found in manual testing, to buffer inaccurate estimates, to compensate for time lost to attrition and personal emergencies, to maintain legacy products (quality issues again mostly). This was alarming, but also an indication that there was an opportunity to improve our productivity greatly for no extra cost by addressing some of the issues. The capacity model not only made these opportunities visible, it quantified improvement as we addressed them. Over the course of the next four releases we got our “payload” capacity up to about 65% by addressing many of these issues, starting with field quality.
Capacity model progression
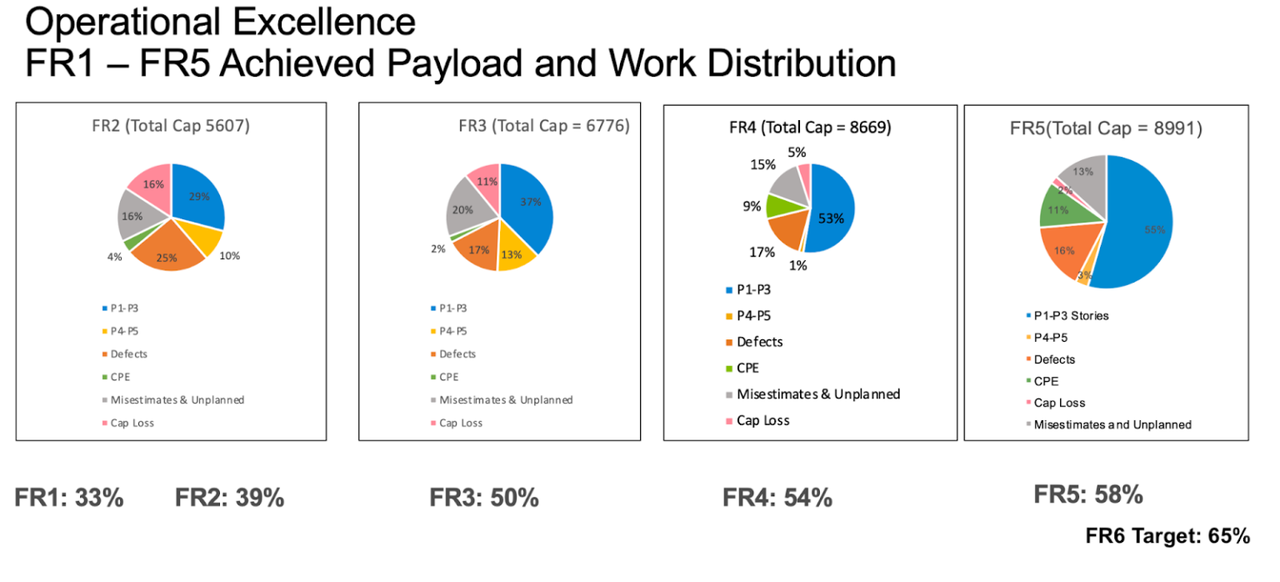
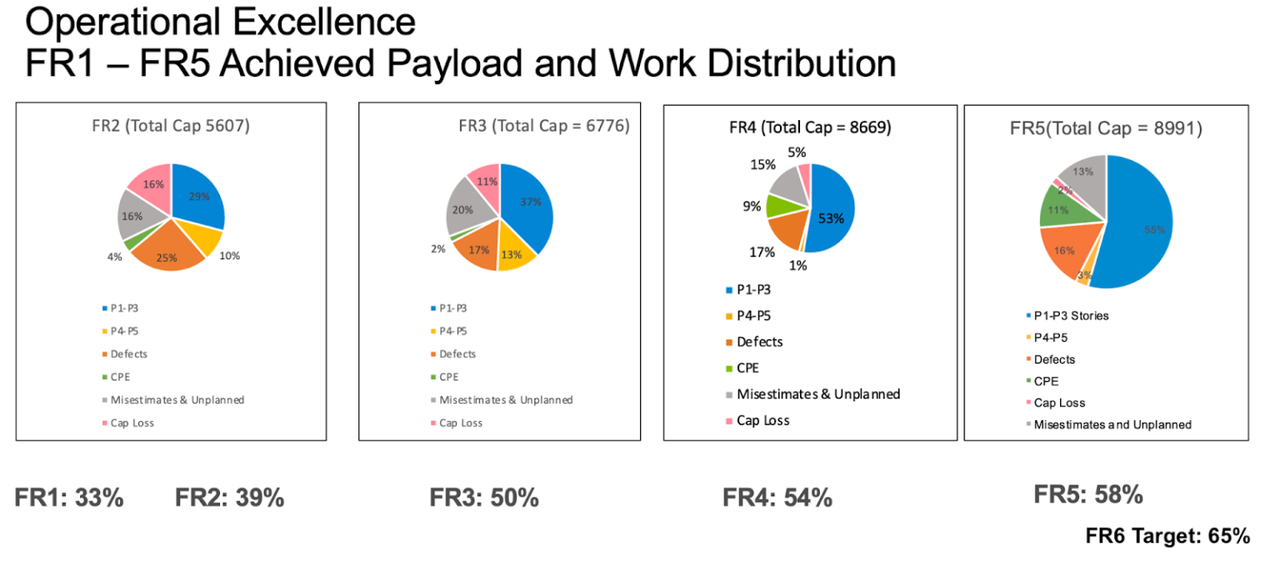
Faster Cycle Time
As we improved our practices we wanted to reduce the planning burden and emotional toll of long release cycles. The emotional toll came from the understanding that if some request was not included in the next release, it would be a whole release cycle before we made another decision, and two cycles at best before that feature might become available. We thought that if we could get a release cycle down to three months (an eternity by SaaS standards), we could relieve this burden and greatly reduce the planning overhead as well. To do this efficiently we had to reduce overhead in our releases. This included the number of sprints reserved for final testing once the code was frozen. We decided to divide our objective into two sub-goals: reduce the time required to run a build and smoke test cycle, and improve our confidence that code that passed the smoke test would integrate well with the rest of the system.
Over time, the DevOps team were able to reduce the cycle to forty minutes - about a hundredfold improvement over the initial state, while growing smoke test coverage. They achieved this mainly by profiling the build and relieving bottlenecks, using containers to automate the deployment of virtual test configurations to remove manual effort from test configuration, and making good choices about what work to do in the quick build and what could be done less frequently.
Results
By FR-6 we achieved 65% payload thanks to improvements in field quality, reduced outsource turnover, and improved developer productivity from more completed work and less planning waste. We continued to scale the team globally and where we had started with two large employee sites and one large outsource vendor, we entered FR-6 with a third large employee site and two more outsource vendors to add scale.
Credibility and Trust with Internal Partners
Credibility and trust were critical to our ability to gain cooperation from our internal partners. Because of the changes we had made, we became the clock that our partner divisions used to time their own releases. Because we were open to good ideas from anywhere and seemed to know what we were doing, we were able to build an outstanding team in Australia to partner with the division there, and the GM of that division made financial sacrifices to fund it.
Credibility and Trust with Customers
Credibility and trust became a competitive advantage as well. Our customers trusted our ability to deliver what we said we would, and mistrusted our competitors on the same scale, that they often treated a feature planned for our next release as if it already existed for the purpose of making purchase decisions. This was a very powerful competitive weapon, a direct result of our emphasis on a predictable cadence of high quality releases.
Measurable Business Growth
We realized direct business benefits from our transformative efforts. OpenLab CDS achieved 65% compound annual growth over the five years from initial release to FR6. It was one of the most successful product launches in company history. These achievements happened because of the dedication and effort of many people at Agilent, especially in SID. It was an honor to have had the opportunity to lead during this time, and a source of lasting satisfaction to me that we achieved great business results by doing well for our customers.