Capacity Models in Agile Development
This paper adds to the Method Matters Podcast with Carlos Taborda from July 2019 (refer to 32:00)
A good capacity model is your secret weapon for improving your ability to deliver value rapidly. This paper describes how capacity models work and steps to develop your own.
A capacity model is a continuously refined artifact that helps to forecast how much work can get done in a given time. At Agilent’s Software and Informatics Division (SID), our capacity model helped us to more than double our productivity over a couple of years. It helped our stakeholders and customers understand what to expect from us at every release. Our capacity model was and still is the foundation of our team’s confidence and our customers‘ trust.
SID does Agile Scrum software development on a global scale. In Agile development, teams work in short cycles called sprints. At the end of each sprint, the team must deliver working software that a customer or stakeholder can evaluate. To do so, they work with a customer or a proxy to write “stories” that can be completed, tested, and demonstrated within a single sprint. They must also estimate how much effort the story needs so it can be sized to fit a sprint. This depends in turn on a solid “definition of done” - the set of conditions that must be met for a story to be considered complete. We learned that a good Definition of Done is critical to success.
To simplify estimation (and keep ourselves honest), we dedicated developers and testers to each scrum team, with a target 6 dev and 3 testers/test developers per team, plus a scrum master and a product owner each of whom typically share two scrum teams. We used a fixed two-week sprint cycle.
We learned to define a “point” of effort as being equivalent to a raw staff day. A reproducible unit of work enables aggregating the capacity of several teams into an estimate of total capacity. we deliver software to market on a fixed 6 month release cadence, and give first priority to quality (both freedom from defects and fitness for use), second to hitting the cadence, and third to scope. The team designs releases so that scope can be ejected if things don’t go perfectly.
A. Preferred
- Quality
- Cadence
- Scope
B. Not this
- Scope
- Deadline
- Quality
C. Nor this
- Scope
- Quality
- Delivery date
We found that it was critical to have a single system of record for all work and estimates (we use Atlassian Jira). This lets us assign work flexibly among teams and generates useful release metrics.
Before we had a capacity model, we planned releases from a ranked backlog of work we wanted done, but found that a lot less work fit our release at the start of development than we had hoped. We were over-planning relative to what we could get done, and disappointing our stakeholders. We made our first capacity model in response to this challenge. Over time, this has resulted in reduced planning effort and much more realistic expectations about what will fit in a release, which leads to healthy give and take during estimation and story refinement.
Our first capacity model accounted for estimation errors, defect fixing time, time for customer emergencies, and time to maintain prior releases. Subtract this from “loaded” staff-days in the release and we had an estimate of capacity for stories delivered to market (“payload”), including development and testing.
To estimate loaded staff-days we relied on a “focus factor” that estimates how much of a developer’s day can actually be used for developing, as opposed to other activities of corporate life. Note: Special thanks to CPrime, our Agile coaches, for introducing us to this idea. We treat Focus Factor as improvable and look for ways to grow it to improve the workplace for developers and testers and increase payload capacity.
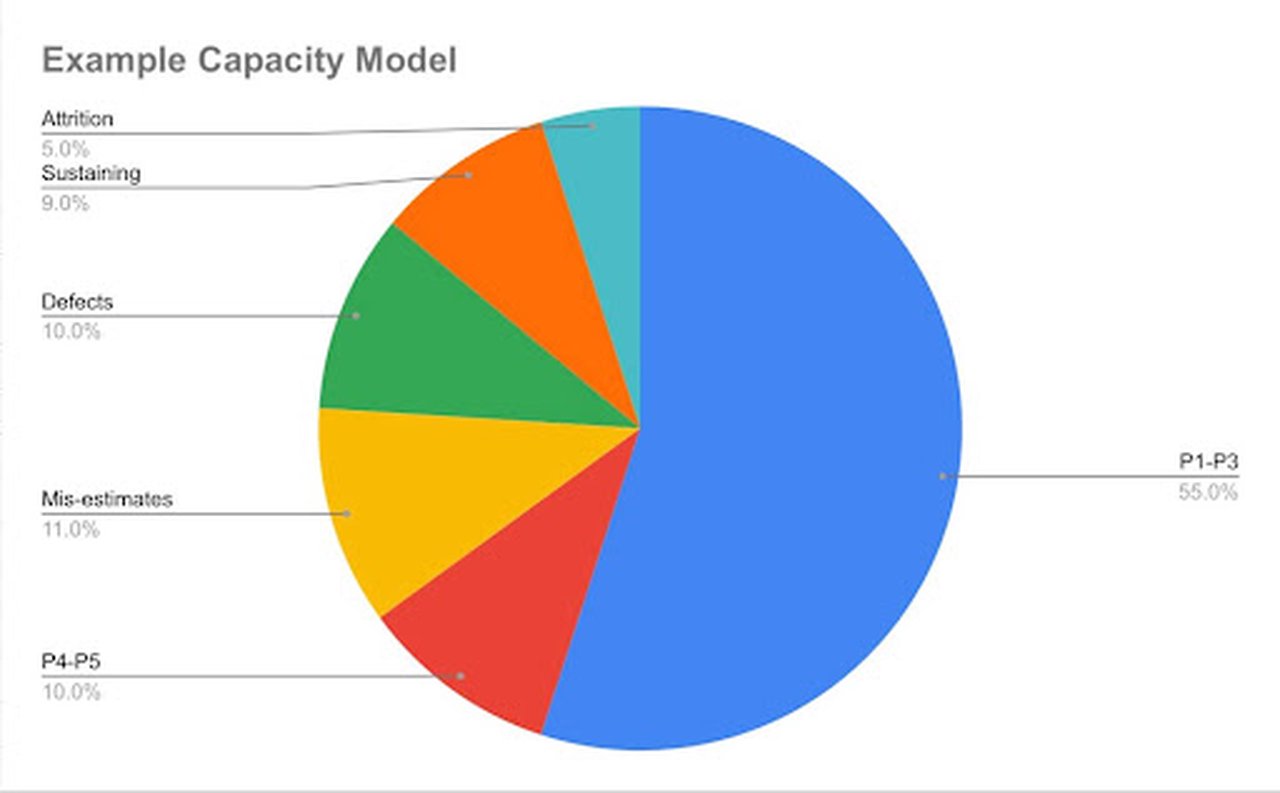
Figure: An example capacity summary showing a total payload of 65% (sum of P1-P3 and P4-P5) and other uses including fixing Defects, Mis-estimates and unplanned work, Sustaining work, and capacity lost to attrition and personal emergencies (“Attrition”). Planning and estimation effort can and should also be included to make it visible.
We refined our capacity model after each release as part of our continuous improvement efforts, using Jira to review how we spent capacity in the release. We identified un-modeled capacity leaks and set realistic goals for improving them over time. We also set goals for activities that can lead to improving focus factor. Because we value trust and autonomy, we do not measure the focus factor individually. Instead, we infer it from aggregate performance and work to improve it based on the evidence we have.
Over time we refined our model to include the capacity required to scale the team (training and hiring), capacity reserve for release planning, time lost to personal emergencies and attrition, and reserves to support cycle time targets for bug fixes. Experience also led us to refine our Definition of Done in response to situations where teams felt pressured to close out stories to be “on track” while pushing defects and technical debt later in the release. In our case, we added the expectation that stories have architectural review and code has peer review, reviewed unit-tests exist and pass, and that all critical and serious defects against the story are closed before a story can be marked “done”. It’s critical to develop a culture that rewards honesty and early action when problems arise. Ultimately it is people and culture rather than processes and rules that create great products and services.
Two more critical learnings from our experience:
Do just enough planning. Continuous grooming and high-level rough estimation give us the evidence we need to minimize over-planning waste, especially important because Product Owner capacity is critical and difficult to scale quickly. Product Owners operate at three levels: portfolio, product, and release backlog. If there is not enough of the right kind of capacity reserved for laying the tracks (architecture and longer-term scope) the release trains will slow down.
Assess technical risk and architectural changes early in each release cycle, then work the risk down early in the release. Otherwise, you will get late surprises and it will be too late to eject scope when the crunch hits. Minimize Work in Process for the same reason - stories and features should be finishing all through the release rather than piled up at the end so that test load is relatively level and risk is reduced early.
Based on our experience, a capacity model can be useful at any scale, individual to enterprise, and applies to any kind of work, although it is especially good for work done with Agile methods because of their transparency. It enables us to answer planning questions, to focus on those things that have a fighting chance of getting built in the next release, and to reflect the real costs of change and waste. With our capacity model, we can confidently predict what we can achieve, how fast we can scale, and improve every time.
If you’d like to give capacity modeling a try, here’s what you need:
- One system of record for stories, estimates, and bugs (Jira for example, but for personal work it could be a spreadsheet, sticky notes, or a paper list)
- A defined release cadence - it’s critically important that the cadence is fixed, and that scope is treated as the dependent variable.
- A reproducible unit of estimation (we define a point as a raw staff day)
- A basic capacity model that you can refine from release to release
- An interaction where the team reflects available feature capacity to stakeholders so that the right amount of backlog gets groomed into each release
- An interaction to review and improve the model after each release
- A rigorous “Definition of Done” to prevent capacity leaks
More on these topics in upcoming papers…